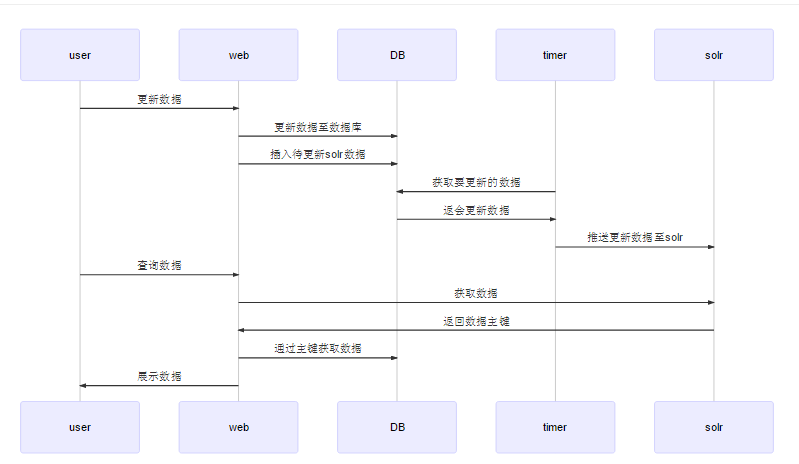
前言
项目使用 thinkphp + mysql 对列表进行查询,列表数据量达到千万级别,且搜索维度效果,故采用elasticsearch进行搜索
为了尽量不改动代码逻辑,需要实现
- 数据自动同步至ES ( 使用 go-mysql-elasticsearch)
- 平滑切换TP自带的数据库查询操作到ES(自定义 query,转化TP 的查询条件为 ES的查询条件)
1 | graph TD |

功能使用
说明
php 中\think\db\query\Elasticsearch 为 处理 TP语法到 ES 中的的查询语法,调用方式通DB 相同
暂只支持where , whereor ,wherein , limit , order ,find select ,value ,sum 方法
- 查询方式
1 | Elasticsearch\Elasticsearch\FinanceBillIncome::where('xxx','xxx')->find(); |
- 列表时 先通过ES 查询出主键ID, 再通过主键 查询出明细数据
- 列表查询通过 count 方法
- 列表头部统计 ,通过如下方式查询
1 | ->sum( [ |
暂不支持 join,必须join 的降级为DB 处理
alias 方法指定后,ES 查询时将 自动去除查询条件与字段中头部别名
使用步骤
先通过
.env
1
2
3
4# 搜索引擎地址
ELASTICSEARCH_HOST_NAME='192.168.x'x.133'
ELASTICSEARCH_HOST_PORT='9200'
ELASTICSEARCH_INDEX_PREFIX='xxx_'database.php
1 | 'elasticsearch'=>[ |
1 | Elasticsearch\Elasticsearch\FinanceBillIncome |
- 初始化 ES,创建 index
1 | /cron/elasticsearch/initSearch |
- 输出的内容 为 go-mysql-elasticsearch 中的配置
- 启动 go-mysql-elasticsearch
监控
- 定时 monitor 表中更新时间
- 定时查询ES 中monitor 的时间
- 对比时间差异,差异时间为延迟时间